Web crawler & finding word lists [fr]¶
J’ai toujours été assez fasciné par les crawlers web. Avec un crawler puissant et rapide, il devient possible de tirer profit de l’énorme quantité d’information présente sur le web, de toutes les façons imaginables. Il y a tellement d’applications possibles !
Je vais ici développer un projet bien précis : un remplaçant du défunt Google Sets : palkeo sets.
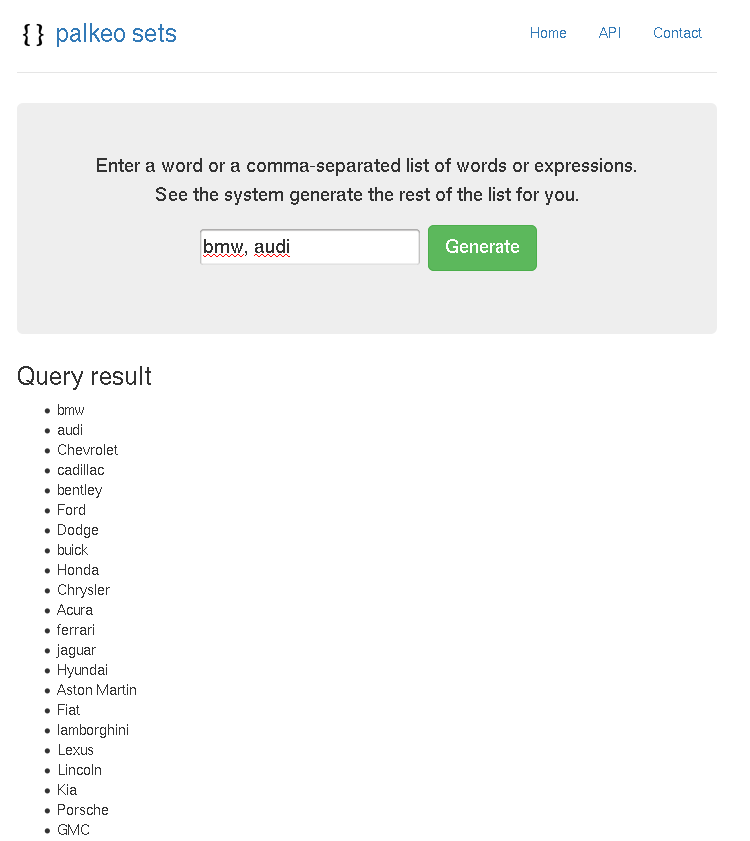
Google Sets permettait, en entrant un ou plusieurs mots, de récupérer une liste des mots faisant partie du même « ensemble ». Ainsi, en entrant une ou plusieurs couleurs, on est censé obtenir les autres couleurs. Mais on peut ausi entrer une ville, une marque, une émotion, le nom d’un artiste ou d’un personnage…
Pour créer un tel service, une solution simple est de construire une grosse base de données de toutes les listes trouvées sur les pages web. Mais cela nécessite un crawler !
Un crawler très simple et rapide¶

Mon objectif a donc été de trouver une manière de faire un crawler de pages web devant être à la fois simple, et très performant.
Au final, j’ai fini par réussir a le faire, en m’appuyant sur deux astuces fort utiles :
Common Crawl : plutôt que de faire soi-même le travail de suivi des liens (qui est bien plus complexe qu’il en a l’air, pour l’avoir testé !), il existe une autre solution.
Common Crawl fournit une gigantesque archive d’un crawl plutôt exhaustif du web. Elle est compressée, et il est possible de la récupérer au fur et à mesure. On minimise ainsi la bande passante, tout en simplifiant radicalement le code et l’utilisation du processeur.
Le parallélisme. Mon crawler tout simple était malheureusement limité par le CPU.
Via le module « multiprocessing » de Python, j’ai pu tout architecturer autour d’une file et d’un système producteur/consommateurs : les calculs sont répartis sur chaques cœurs, et les performances s’envolent.
Au final, j’ai un crawler qui tient en 100 lignes de Python, et qui parse 500 pages web par seconde en moyenne. Sur mon serveur personnel avec un Intel Atom.
J’ai calculé qu’avec 100 machines, je devrais pouvoir crawler le web (où du moins la gigantesque portion publique fournie par Common Crawl) en une semaine.
Le crawler est disponible sur GitHub : palkeo/commoncrawler
Traitement des données brutes¶
Le principe du crawler est de recracher sur la sortie standard toutes les listes qu’il trouve dans les pages web. Pour passer de ces listes à une base de données utilisable, il y a un peu de travail.
Ma base de données est plutôt simple : pour chaque couple de mot, elle contient le nombre de fois ou ces deux mots ont été trouvés ensembles dans une liste. En réalité, je construis donc une sorte de graphe non-orienté pour chaque mot, et je suis sûr qu’il y aurait moyen de faire plein de choses géniales avec des algorithmes sur ce graphe.
Problème : mon fichier brut de sortie de mon crawler fait 60 Go (oui, j’ai crawlé des centaines de millions de pages web et ça m’a pris quelques jours). Il me faut ensuite éliminer les listes redondantes, extraire les couples de mots, compter les occurences de chaque couple… Malheureusement, impossible de faire tenir ne serait-ce que la liste des mots en mémoire, il y en a bien trop.
J’ai donc opté pour une solution maison qui s’est avérée plutôt efficace : chacune de ces étape peut se décomposer en un tri de ma liste (map), suivi d’une opération pour générer un nouveau fichier (reduce). Chaque étape de parsing et génération d’un nouveau fichier est très simple, et le fichier étant trié, je n’ai jamais besoin de garder des listes en mémoire.
Pour trier le fichier, il m’a suffi de faire appel à la commande « sort ». Elle est en fait extrêmement puissante/configurable, et a l’avantage indispensable de ne pas trier en mémoire, mais d’utiliser des fichiers intermédiaires. Cela prenait quelques heures, mais fonctionnait impeccablement bien même avec des fichiers de plusieurs dizaines de giga-octets.
palkeo sets¶
Au final, j’ai donc pu développer un service qui peut remplaçer le défunt Google Sets : palkeo sets.
Je suis persuadé qu’il pourrait servir, en particulier à des personnes faisant du référencement et cherchant des mots ou expressions similaires à celles qu’ils ont déjà.
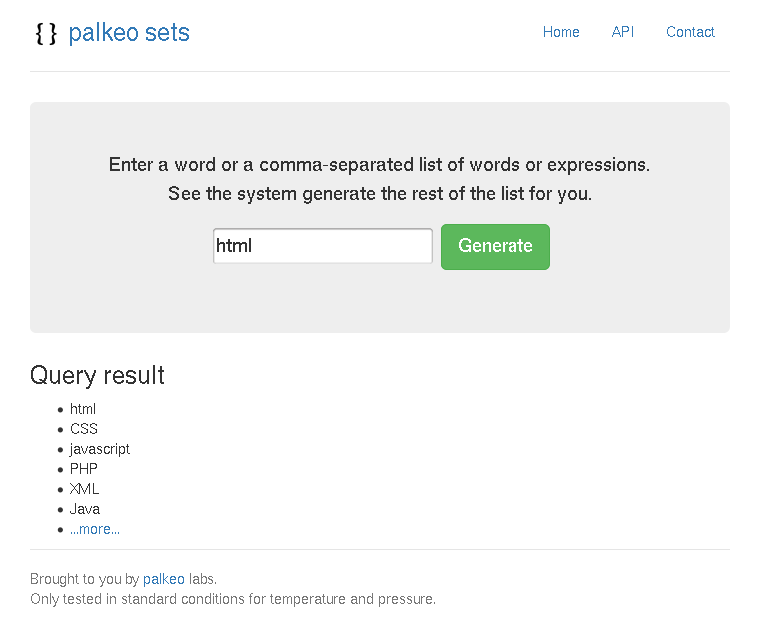
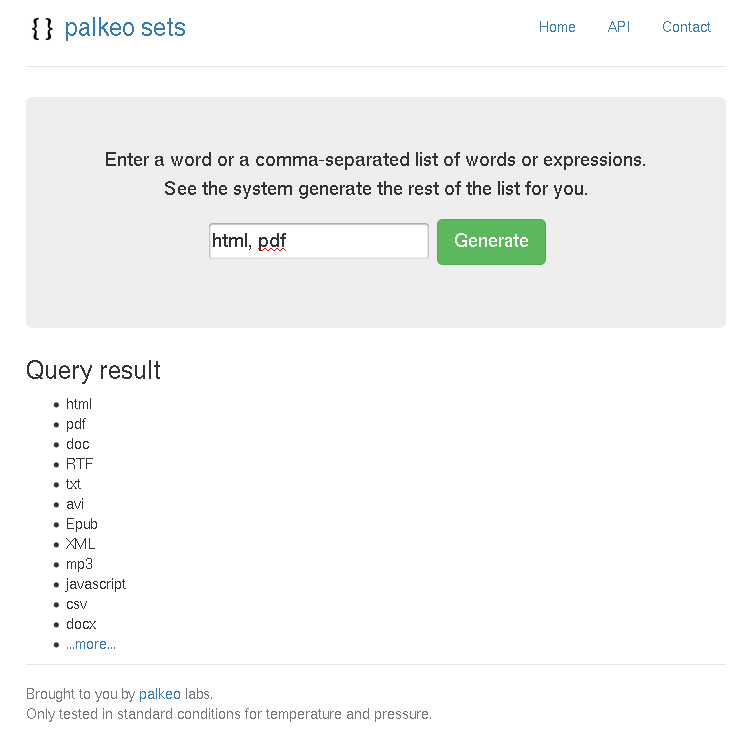
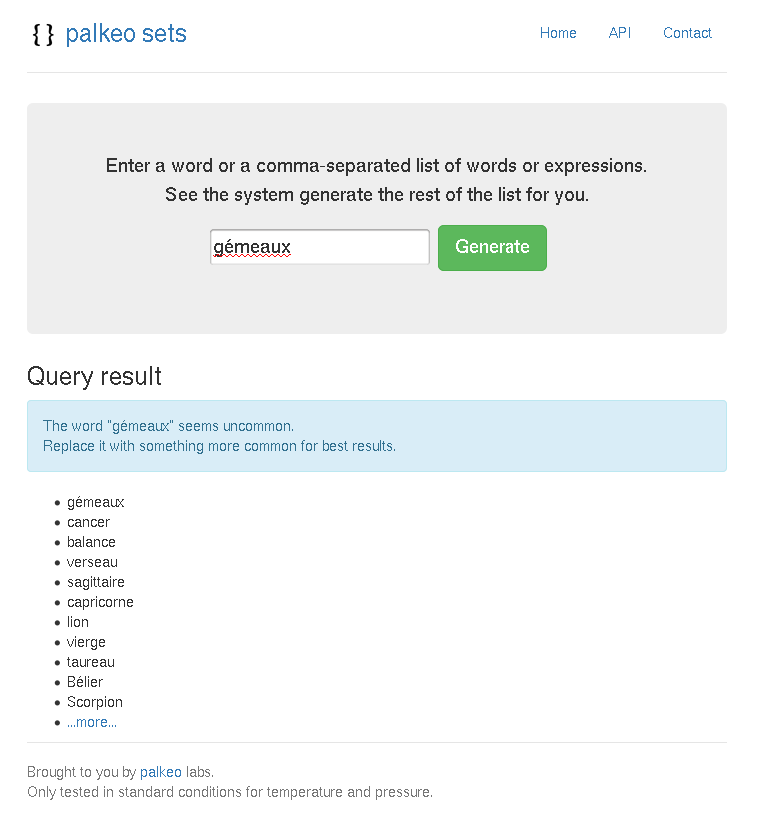
Voici quelques captures d’écran :