Feedspot [fr]¶
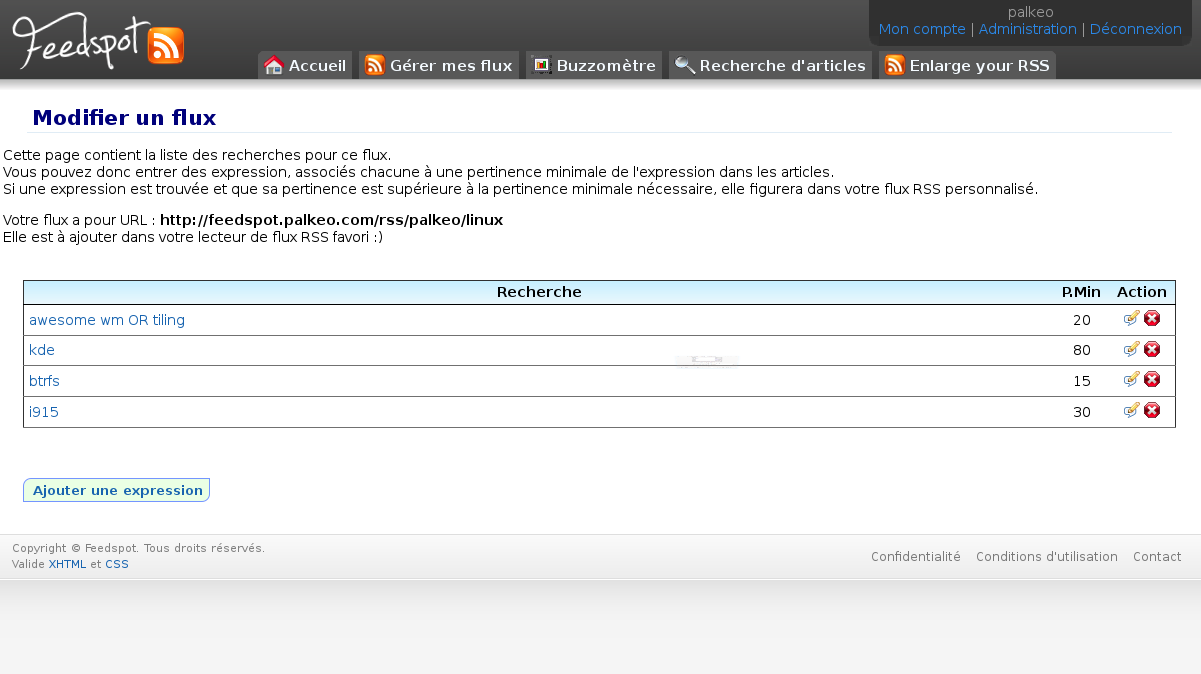
Feedspot est parti de l’idée que les flux RSS représentent une source gigantesque de données brutes, directement exploitables, et toujours à jour.
J’ai donc créé un ensemble de scripts pour découvrir un maximum de flux RSS : J’en ai actuellement plus de 150 000. Puis, je récupère les flux de manière régulière, et j’indexe leur contenu dans ma base de données.
Autour de cette infrastructure, j’ai développé plusieurs services :
L’outil de flux dynamique, permet d’obtenir automatiquement tous les articles qui mentionnent un sujet, ou contiennent certains mots clés… Utile pour surveiller tout ce qui parle d’un sujet/nom/site…
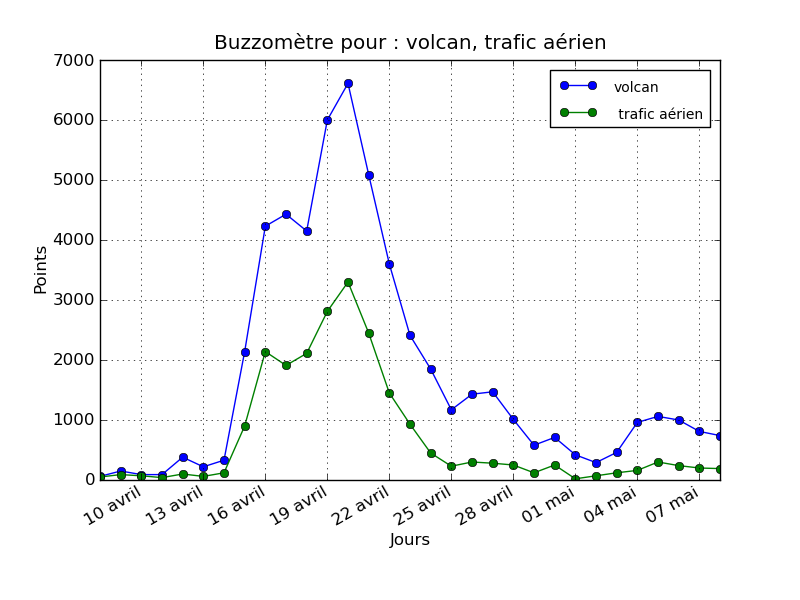
Le buzzomètre : à partir d’une expression, il est possible d’obtenir une courbe interactive qui représente la présence de ce mot clé dans l’actualité (en gros, le nombre de fois ou l’expression est parue).
Le radar à buzz propose une sorte de frise chronologique qui contient tous les mots qui ont « fait le buzz » au fil du temps. Plus on dézoome, plus on aura une vision « globale », avec seulement les expression qui ont le plus fait parler d’elles.
J’ai aussi développé un outil qui permet, à partir d’un flux RSS contenant uniquement des articles tronqués (on a seulement la première phrase, et on doit aller sur l’article pour le lire en entier), d’obtenir un flux dans lequel les articles apparaissent bien en entier.
Et, au vu du volume de données qui arrivent et de ma façon de les stocker, je suis persuadé qu’il y aurait beaucoup d’autre choses intéressantes à en faire…
Le système d’indexation¶
Lors des débuts de Feedspot, j’utilisais PostgreSQL et son système d’indexation plein-texte, mais il s’est assez vite révélé inadapté.
Étant donné que je suis très intéressé par la recherche et les méthodes d’indexation, j’ai décidé de développer moi-même un système complet d’indexation, qui maintient un gigantesque index inversé.
Pour chaque mot, je maintiens donc une liste des documents dans lequel il apparaît (et des positions de ces mots dans les documents, pour la recherche d’expressions exactes) Par contre, je stocke le tout dans des fichiers, et j’ai donc un fichier par mot : C’est une solution vraiment loin d’être idéale.
J’ai découvert l’utilisation du delta-encoding couplé à de l’encodage à taille variable, pour permettre de réduire énormément la taille des index. C’est d’ailleurs impressionnant de voir le gain de vitesse en compilant la fonction de lecture de ces nombres en inline.
Dans mes tests, en indexant l’intégralité de Wikipédia fr, il s’est révélé légèrement plus rapide que le moteur de recherche utilisé par Wikipédia, semble-t-il.
J’ai aussi dû développer un parseur, utilisant la technique du shunting yard, modifiée pour les expression exactes.
Si vous êtes intéressé, je vous conseille de regarder du côté de Xapian, en particulier ceci.
Le code de base de mon index inversé est également disponible (fonctionnel, mais sans les parties spécifiques à Feedspot) : indexd.tar.gz.
Détection de mots clés qui buzzent¶
Disposant de mon système d’indexation, j’ai pu le modifier pour un usage bien spécifique : Calculer des sortes de « buzzomètres » pour chaque mot clé, et détecter les mots clés qui montent.
Pour cela, il me suffit, à chaque mise à jour d’un fichier d’index pour un mot clé, de mémoriser le nombre de « hits » par jour, à la recherche de pics anormaux. Je dispose dans ma base de données d’une table dans laquelle je vais pouvoir stocker tous les pics de mots clés.
Toutefois, il faut aussi être capable de supprimer les pics qui sont en fait des parasites (par exemple, un flux qui produirait 10 000 articles contenant tous un mot clé, créerait un tel pic). J’ai également rajouté un algorithme pouvant grouper les pics qui vont ensemble, et un autre qui « étend » le mot clé, pour qu’on puisse avoir une expression complète ayant du sens au lieu d’un mot clé (sans accent, en minuscule, au singulier…).
Web design¶
J’ai aussi créé l’intégralité du design moi-même, avec pour but d’avoir quelque chose de joli tout en restant le plus léger possible.
Les pages sont donc en HTML5, et n’utilisent quasiment pas d’image : Les dégradés et ombres sont tous fait en CSS. Les seules images sont celles du menu et le logo, tout le reste étant fait dans le CSS.
Le design peut également s’adapter à la taille de l’écran qui le consulte, et fonctionne donc bien sur téléphone.
Graphiques interactifs¶
Les graphiques interactifs ont été faits avec la librairie flot.js (basée sur jQuery), et plusieurs de ses plugins.
Lorsque les graphiques sont modifiés (zoom, déplacement…), des requêtes sont faites à mon serveur qui renvoie les courbes sous forme de JSON.
Toutefois, le « radar à buzz » n’utilise pas flot pour l’affichage, et fait des choses plutôt sales en positionnant des éléments par-dessus une courbe vide…