Un crawler très simple et puissant en Python [en]¶
I am fascinated by web crawlers since a long time. With a powerful and fast web crawler, you can take advantage of the amazing amount of knowledge that is available on the web.
You can do simple treatments like statistics on words used on millions of web pages, and create a language detector, for example ! Or more complex ones like calculating the relation between each page (and create a graph ! reinvent Pagerank !)…
Personally, I was frustrated by the death of Google Sets and wanted to create an alternative. But my goal was to crawl hundred of millions of webpages to have a good accuracy. And I didn’t know how to crawl so much with a simple crawler, on my personal server.
At the end, I did it in one week with approximately 100 lines of Python. It was crawling 500 webpages per second, on average (on my personnal server with an Intel Atom). I have calculated that with 100 machines, I could have crawled the web in one week.
Common Crawl !¶

The first step that really diverged from classic crawlers, was to decide to use Common Crawl instead of reinventing the wheel.
At Common Crawl, they provide you with a HUGE archive, containing an « image » of the web. Their images are quite exhaustive, as they contains petabytes of data (billons of webpages). And you can get the HTTP requests and response for every webpage !
However, I was not able to find a simple example crawler to play with.
The best I found was using Hadoop, and was made for being executed on Amazon Elastic MapReduce. That is nice for crawling the whole web efficiently, but I needed something more simple for me to understand and hack it !
I also didn’t wanted to download these huge files containing crawl results. And I have seen they could be streamed…
Simple, but amazing crawler¶
So, I decided to do a crawler of my own, that would be as simple as possible.
At the end, you just have to stream the archive you get from common crawl. And then, you can do whatever you want on the web pages.
However, I was a little disappointed by the performance of my crawler, as the main bottleneck was clearly the CPU. But it was not so surprising, it is in Python, with a lot of string manipulation…
So, I after trying various tricks I was amazed by a simple one : the producer-consumers pattern ! However, because of the Global Interpreter Lock, you can’t really take advantage of the threading in Python. But there is the multiprocessing module that is very similar, without GIL.
I ended up having a process that will download the archive and put webpages in a queue. On each CPU core there is a worker that will consume the webpages available in the queue, and print the result to the standard output.
In the end, the crawler is around 100 lines of code. It is quite simple and during my tests the bottleneck was the bandwidth to download the crawl data, and not the CPU !
You can find the crawler on GitHub : palkeo/commoncrawler
What can you do with it ?¶
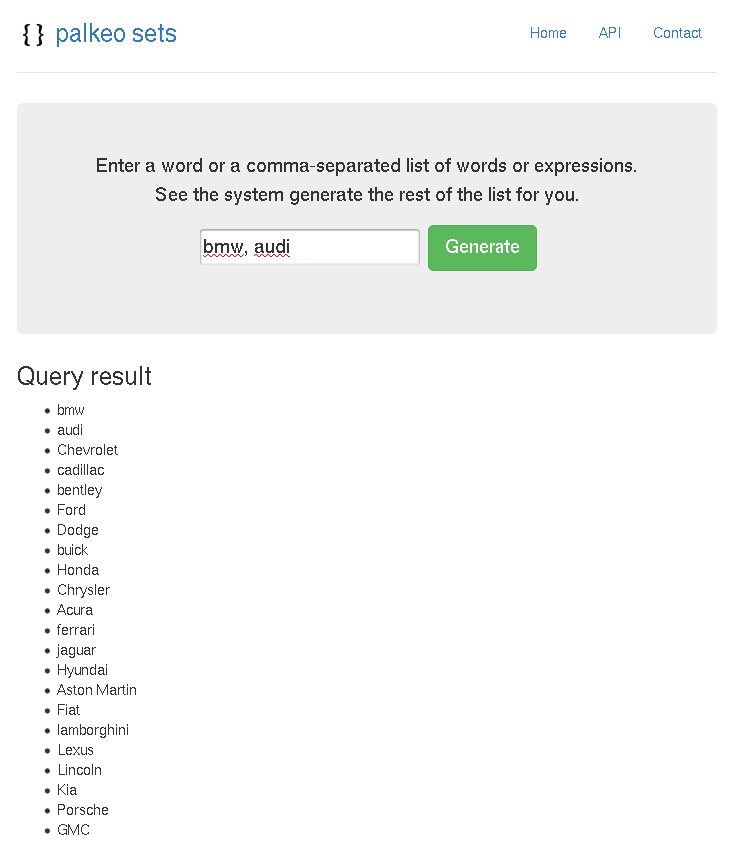
Personally, I have used a script really similar to this (just a little more complex) to extract lists from webpages. At the end, I had a HUGE file (>60 Gb) containing all the lists encountered. I took advantage of the « sort » command that can sort files without any limit on their size, and created a little pipeline to count or eliminate duplicate at each step. And filled a database.
I ended up with this service, which works quite fine and generate words that belongs to the same set as the words you enter.
But there are so much things you can do with it ! And what’s awesome is that you can easily split the WARC file to split the work on more than one machine (if you have bandwidth…).
Of course, if you are really serious about it and you have a lot of servers, it is always better (but more complex !) to use a more specific tool like Hadoop and mrjob, for example.
Have fun :)